|
The Website Blisworth.org.uk/images This
is about the
"Climb" and then the "Glide", the enhancements to
the website Tony Marsh, February - July 2015 The Start: Blisworth.org.uk/images was first posted in 2005 in order to show old photos of the village and village people. Such photos were coming to light in large numbers, particularly after it was realised that George Freeston had submitted documents and photos nine years earlier to the N.R.O. He did not publicise that action. All was available to the public at the N.R.O. with free use of a camera in the Reading Rooms at the time. Making the photos widely available was seen as something that should be controlled by some, as though some profit must accrue from their release. Setting up the website was opposed by some for that reason but within 3 years such opposition had vanished. The first release of the index page is shown below and carried just four links to some Photograph Collection Pages
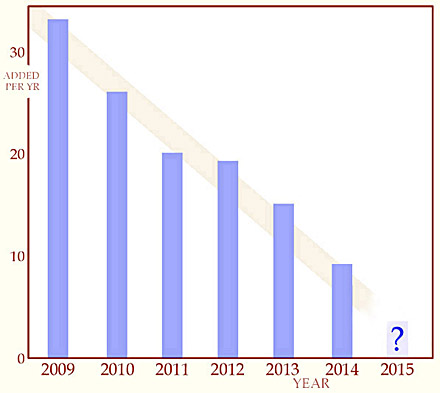
The cover (or root) page blisworth.org.uk is not included in the account here. It simply displays an assembly of links to other societies in the village and as such may not be of much use to anyone! Growth in Early Years: The number of photograph collection pages rapidly rose to over 40 with some in fact divided and extended with up to three extra pages so that visitors would experience a reasonably speedy loading of each page. There was no broadband then and consequently most of the image files were stripped of their textual content to minimise their size. Many contributors of photos were keen that they should be water-marked with a title ("Blisworth Images") in order to exercise some control over their use by others. The copyright of a majority of the images has never been clarified. With recent changes in copyright law the availability of high resolution versions of images has been discontinued, particularly to 'media' people. Quite a few villagers came forward with photos, there are well over 2000 in total, and some also offered their accounts which they either gave verbally or as written texts. There was also a large amount of further material which was deposited at the N.R.O. after George Freeston died in 2001. Once this had been sorted by members of the heritage society, the images and texts in this second tranche were examined closely. This encouraged a few people to extend their own researches and offer their own texts to join the others on-line. Interest in the website grew and by 2007 there were 700 to 900 visitors per month to the pages according to "Google Analytics". About half were repeat visitors who represented the core interest whilst the others were potential future repeat visitors who may have, however, simply landed on the site by following a Google search function. These figures have been in serious doubt since the research through server logs in June 2015 - see below The Addition of Topics: Subsequent to the main activity of filtering material at the N.R.O. new subject pages have been added regularly and, for example, stood at a rate of 33 new topics per year in 2009. The rate has fallen off in recent years and was down to only 8 or 9 new topics about the village in 2014 as shown in the chart below (March to March years). There are however a present total of just over 500 topic pages (though sometimes they are in groups and closely related). The total size of the site in digital terms stands at 530 megabytes.
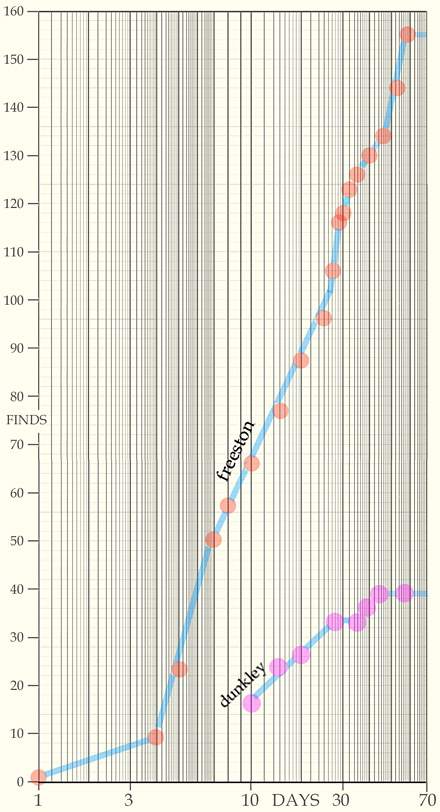
A Slight Hiccup: Through September to November 2014 the website has been off-line while a clean up of orphan pages and a check on the copyright situation was carried out. This unfortunately encouraged Google to entirely forget its indexing of every page on the site. So when the site was opened again on December 1st a site-search produced absolutely nothing on any subject at all. Google promptly reactivated its indexing and within 24 hours it had processed the large file holding the historical index. Out of interest I repeatedly tested the indexing using an appropriate keyword (eg: "freeston" or "dunkley") in the search box, over the following many days. I was interested in how long it would take Google to complete a site index and thus be able to find virtually everything. As shown in the chart to the left, this 500 megabyte site required at least 60 days. The circumstances were somewhat favourable for the Google search "bots". Evidently they indexed the more recent material first and eventually finished with the oldest. Then they caught up with some of my very recent editing within 40 days and then proceeded to dig deeply for another 20 days and seemingly finished the task. About George Freeston: One may deduce, erroneously, that the website is chiefly about George Freeston in view of the fact that there were found ~160 references to either him or his family by Google throughout the total number of webpages (~510). A majority arise from the need to cross- reference in order to help "ground" our readers so, for example typical of many webpages, the one at ../chapel/staughtontree.htm has a Note 5 there for something that is merely incidental whilst the webpage has nothing to do with George Freeston. Fortunately, Google ranks the finds and tends to present the important ones near the top. There are about 45 of these important references and they refer in particular to George Freeston's research and articles. In this document those 45 are highlighted orange. In the same document a blue tab is used to identify the top 12 references that are found in Google's ranking, a ranking which proved to be actually rather successful. The collected references to Freeston often include the point that a particular photograph came from his collection. What is hidden here is that he probably collected about 500 photographs - often from villagers. I trust that the document that lists a majority of these references, in alphabetical order, serves as a fitting tribute to all his work over a period of about 45 years; for his talks and his efforts in collecting, rescuing, discovering, interviewing and project following, for his writings and his cut-an'-paste displays employed often in the village hall or in the church in an age well before domestic computers. His graphical skills and his imagination are well represented in his view of the old bacon factory included in his 1953 scrapbook. It occupied a strip of land that ran from the Stoke Road, adjacent to the Village Hall, back as far as Home Close. The view from the north that George Freeston offers is very elucidating, see this article, but could never have been seen at the time; he has removed the foreground clutter of houses along the High Street and thus created an easily understandable piece. George must have spent hours on presenting the village and its story in this sort of fashion - for the villagers. He rarely published for County readers.
Some Thoughts about Google: The "curve" of finds versus time shows a pronounced log10(t) character. Perhaps, if the incidence of keyword locations were perfectly random the curve would be a good straight line. That would be expected because Google's "reference book" for the website would expand during the 60 days as various words (both within Google's dictionary and ones that are distinct to the website) are accumulated and so the rate at which new finds can be positioned and inserted into the book must therefore decrease (linearly?) with elapsed time, hence the logarithmic trend. Of the 530MB total on the website, only 10MB is text. By the time of index-completion the bots would be running through the last bit of text at a rate of about 50 words per hour having started at a rate ~1000 words per hour. By now the site is fully indexed and users should encounter no difficulties. However, if a page is reported by the browser to be missing then perhaps the visitor could report it at Contact. The present number of visitors according to Google Analytics is roughly at the rate of over 1300/month with a surge in May 2015 (60% are non-UK English-speaking) with a 90% proportion of new visitors. A recent revelation has come from an analysis of the web host's server over a period beginning in mid-June 2015. Previous estimates of the website's activity have been under-estimated, it appears, and it is now estimated the perusal of web pages (htm, html) and documents (doc, pdf, etc.) is at the rate of 3600 site access sessions per month. The total server delivery is ~150000 files/month but the majority must be discounted for a variety of reasons (some associated with the frenetic nature of internet activities mainly associated with the support for searches, an activity greatly enlarged by the prevalence of smart 4G phones. This subject is dealt with in more detail below - a paragraph to be completed in due course. An indication of the website's hotspots, in respect of interest shown, is to be provided below. Separate from that is the general conclusion, from search records over the period 2007 - 2011 (statistics once furnished by Google but that has now ceased) there appears to be some fall off in curiosity in the site. This may be a product of a fall off in what is effectively the rating of the site by Google and other search companies which might in fact be more inclined to favour anything new that appears on the internet. For example, a few years ago a search for Hereward the Wake on the internet would include this site which was fairly new then, admittedly rather remote from the top, but a retry carried out recently (using helpful page daisy-chaining software) failed to discover this near-decade-old site in the first 500 entries, ie. the first 50 pages. The act of putting "Blisworth", as well, into the search string, after Hereward, brings this site right to the top and this demonstrates a key tip for searchers, which is to always put what you know into the search string as the engines make selections by association. What is to Come? We need to bear in mind this is an infant industry - nothing is constant. The sources of the History of Blisworth is the N.R.O. (the prime source, un-catalogued) along with certain additional sources such as the "cupboards" of the Blisworth Heritage Society, the 1953 Scrapbook compiled by George Freeston and the follow-up 2013/2014 village scrapbook compiled by the BHS. Further additional sources are a personal computer hard drive partition (also the BHS computer) and, of course, this website with its free Google-indexed access on the homepage. These sources, although comparatively tidy and catalogued, may not be available in 25 years time. For how long should we assume Google will be able to thoroughly index web sites, in their millions? Indeed the internet, as we now know it, might not be available either, possibly ruinously cluttered up with the 'immediate'; ie. the trash generated by social and domestic connections. Anyone skeptical of this pessimism may not have noticed the occasional world-wide crashes for over 24 hours of some key websites, especially near major shopping days notable in our society. Webhost Server Activities (also an apology for making this section so long) Those companies that construct indexes and surveys for 'app' users account for over 90% of the accesses to the server. They are all expected to look for a plain text file in the root entitled robots.txt to see if there are any off-limits areas of the website they should not survey. For the July 2015 assessment month a robots.txt file was written to prohibit access to all the 'slideshow'-formatted photo albums. This resulted in fewer total accesses, 125989 in fact, of which only 8520 were valid htm* accesses. Some of these however arose when a search engine has suggested a synopsis that was not wanted. The visitor spends a few seconds and moves back to the list of search suggestions and, from previous experience gained with 'Google Analytics', about 66% of such single page sessions are a waste. Single page sessions were detected in the access list and 66% were discounted (without knowing which 66%). This leaves a page access count of about ~7050 in about 3600 'valid' sessions (ie. an average page/session number of nearly 2). The number of htm* pages that were (actually multi-) opened was 708. In the surveys done through June, some 30 ip addresses were stripped from the record of accesses because it was evident the interest was in creating an 'experts' summary of the website or, by virtue of either their using multiple ip addresses to hide their activity or the fact that their ip address had already been black-listed for generating spam or malware. Often the location of these ip addresses turned out to be in Ukraine, Russia, (East) Germany or China. Obviously any access originating from bing, yahoo, google etc. or some other group using 'bot', 'crawler' or 'spider' in their descriptors were stripped from the access list and this is why it is fair to say that over 90% of server response is of no value in assessing how well the website is working. The session total (~3600) for the month was divide thus: about 370 were routed directly through the home-page and then either the search-box (about 80) or one of the general home-page links. All the rest must have been directly routed to a page of interest by using Google, or some other, with a search string such as "blisworth tunnel" and then recognising the page of interest within usually the first ten entries. The other methodology (of taking a look at what was available on the website) was not favoured. This was indicated by the low number of accesses to the historical index (25). Incidently, for those who chose the site-search box the interest was divided equally between either a person/family or a building or a topic (such as boats, oddfellows, post office etc). Pages of interest are as follows: Boat decorations (JP) - 210, Blisworth tunnel - 191, Blisworth 2003 book (AM) - 187, Church notes (GF) - 143, Rumbold (on Weedon) - 110, Rails (1) - 100, Wake History - 105, The Grafton-cards - 92, The tunnel story (AM) - 91, History of weedon - 75, Millner - 77, Blisworth Arm - 72, Listed buildings (BA) - 67, Rails four & three - 67,72, Pillow-mounds - 64, R&A articles (GF) - 64, Saltway - 60 and Droitwich (AM) - 37, Payler, barlow & fellows - 60,63, People (3) - 62, Blisworth mill - 58, Census - professions (RF)- 55, Schools - 54, 'Walks' Tour to Stoke (AM) - 54, Bacon Factory - 50, Russian oil depot- 50, Our Red Wheel - 49, Baptmarrburial 1547-1771 - 45, Church records (JB & GF)- 44, Payler, gucccbw - 44, Post offices etc - 43, The new-marina - 42, The Blisworth baptists (SD) - 39, Old Routes map + text (AM) - 39,39, The 2013 festival - 38, Payler, wren - 37, Tunnel Repairs -1982 (GF) - 36, Walks and legging - 35, The map of local websites - 35. And on and on the list goes - all 708 of the pages that were accessed (Note, there were 21 accesses to this page, before the addition of this section). Of the 708, 370 were 'subject' pages out of a total ~500 pages available on the website (the remainder were html sub-album pages that displayed just one photo). I derive a personal satisfaction from the fact that, in just one sample month the data 'penetration' was 370/708 ie. over 50%. There will be a repeat survey carried out in the mid-Winter.
|

 The Present Position:
The Present Position: 